화면 녹화 1100만 시간으로 학습한 컴퓨터 에이전트: Standard Intelligence FDM-1 (si.inc) ↗
- 핵심 주장. Standard Intelligence가 공개한 FDM-1은 “사람처럼 마우스·키보드로 컴퓨터를 쓰는 AI”의 첫 범용 모델이라 자칭. 지금까지는 스크린샷에 외주 인력이 라벨을 붙여 학습시키느라 비싸고 몇 초짜리 맥락밖에 못 다뤘는데, 이번엔 1100만 시간짜리 화면 녹화 영상으로 학습
- 비유 한 줄. GPT-3가 인터넷 텍스트로 만들어졌듯이 컴퓨터 에이전트는 인터넷 영상으로 만들어야 한다는 발상. 같은 길을 영상에 적용
- 시연 셋. Blender에서 톱니바퀴 만들기(CAD), 1시간 미만 데이터로 미세조정해 샌프란시스코 한 블록 자율주행, 은행 앱을 무작위로 눌러서 “송금 완료 후에도 송금 버튼이 눌려서 마이너스 잔고가 되는 버그” 자동 발견
- 압축 효율. 토큰 100만개에 30 FPS 영상 1시간 40분 담음. 기존 최고치보다 50배, OpenAI 영상 인코더보다 100배 효율적
- Standard Intelligence PBC가 2026년 2월 공개한 자사 첫 컴퓨터 액션 모델 발표 글. 모델 가중치는 비공개, 기술 리포트 형식
Standard Intelligence는 어떤 회사인가?
- 샌프란시스코 기반 소규모 AI 연구 랩, PBC(Public Benefit Corporation) 형태. 자체 표명 미션은 “정렬된(aligned) AGI 만들기”
- 최근 Sequoia·Spark Capital로부터 7,500만 달러(약 1,000억 원) 신규 투자 유치. Sequoia 측 파트너는 Sonya Huang·Mikolaj Ashwill, Spark 측은 Yasmin Razavi
- 엔젤·자문진이 더 눈에 띔. Andrej Karpathy(OpenAI 창립 멤버, Tesla Autopilot 디렉터 출신, 최근 Sequoia “vibe coding” 강연으로 유명, 현재 교육 스타트업 Eureka Labs 운영), Milan Kovac(Tesla Optimus 휴머노이드 로봇 엔지니어링을 이끌었던 인물), Stanley Druckenmiller(미국 헤지펀드 업계 전설로 꼽히는 투자자)
- 시사점. 컴퓨터 사용 에이전트(CUA, Computer Use Agent) 카테고리에 자율주행·휴머노이드 로봇을 했던 톱티어 인재가 자본·자문 양쪽으로 모이고 있다는 신호. Karpathy는 Tesla 자율주행, Kovac는 Optimus를 거친 뒤 다음 트랙을 컴퓨터 사용 에이전트로 본 셈
왜 화면 녹화 영상으로 학습해야 하나?
- 지금까지의 컴퓨터 에이전트 만드는 법은 거의 다 같음. 큰 비전·언어 모델을 가져와서 “이 스크린샷에선 이 버튼을 눌러야 함” 같은 라벨을 사람이 일일이 달아 미세조정하는 식
- 한계가 분명. 사람 라벨링은 비싸고 느려서 데이터가 적게 모이고, 한 번에 다룰 수 있는 맥락도 몇 초짜리에 그침. 30 FPS 같은 빠른 영상은 토큰이 폭발해서 처리도 못 함
- 글의 핵심 발상. 컴퓨터 에이전트도 GPT-3가 텍스트로 했던 길을 똑같이 영상에 적용해야 함. 인터넷에 이미 굴러다니는 화면 녹화 영상을 통째로 학습 코퍼스로 쓰자는 것
- 그래야 1시간짜리 워크플로(예: 디자이너가 Blender에서 모델링하는 흐름 전체)를 모델이 한 번에 본 적 있는 단위로 다룰 수 있게 됨
화면 녹화는 왜 별도 인코더가 필요한가?
- 일반 영상이나 책은 정보 밀도가 거의 일정함. 영화 한 컷이든 책 한 페이지든 단위 시간/면적에 비슷한 양의 의미가 담겨 있어서, 일정한 크기로 잘라 압축해도 손실이 적음
- 화면 녹화는 다름. 빈 화면에서 마우스만 까닥거리는 1초와 깨알같은 코드 페이지가 가득 찬 1초가 같은 영상 안에 섞여 들어옴. 두 구간의 정보량이 수십~수백 배 차이남
- 기존 영상 인코더는 토큰 크기가 고정이라 둘 중 하나만 선택해야 함. “화면 텍스트까지 읽으려면 압축률을 낮춰야 함” 아니면 “영상 길이를 늘리려면 압축률을 높여야 함”. 그래서 긴 컨텍스트와 정밀한 텍스트 인식이 양립 안 됨

- 이번 인코더는 압축률을 화면 상황에 맞게 자동 조절. 학습 방법은 자기지도(self-supervised), 즉 프레임 일부를 가린 뒤 나머지만 보고 맞히는 식. Meta가 발표한 V-JEPA의 핵심 아이디어와 비슷한 줄기. 사람 라벨이 필요 없으니 1100만 시간을 그대로 먹일 수 있었던 이유
- 결과 1. 표준 비전 트랜스포머(ViT, 이미지를 작은 패치로 잘라 처리하는 일반 구조) 베이스라인 대비 화면 텍스트 전사 과제에서 학습 수렴 속도 약 100배. 같은 계산량으로 정확도가 훨씬 빨리 올라감
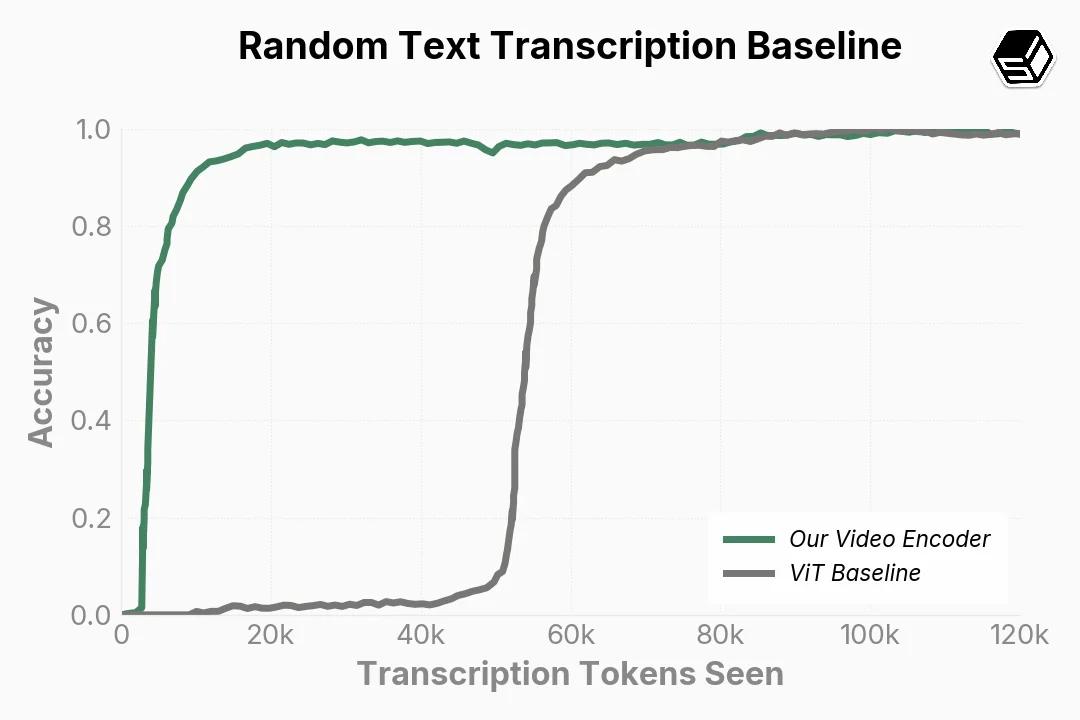
- 결과 2. 컨텍스트 창별 담을 수 있는 영상 길이가 32k 토큰 = 3분 30초, 200k 토큰 = 20분, 1M 토큰 = 1시간 40분. GPT·Gemini 인코더로는 같은 200k에 훨씬 짧은 영상만 들어감
- 그래서 영상은 길게 담되 화면 위 작은 글씨도 또렷이 읽는 게 동시에 가능해짐. CAD처럼 1시간 가까이 가는 워크플로가 학습 가능해진 게 이 인코더 덕
학습은 어떻게 진행되나? (3단계 레시피)
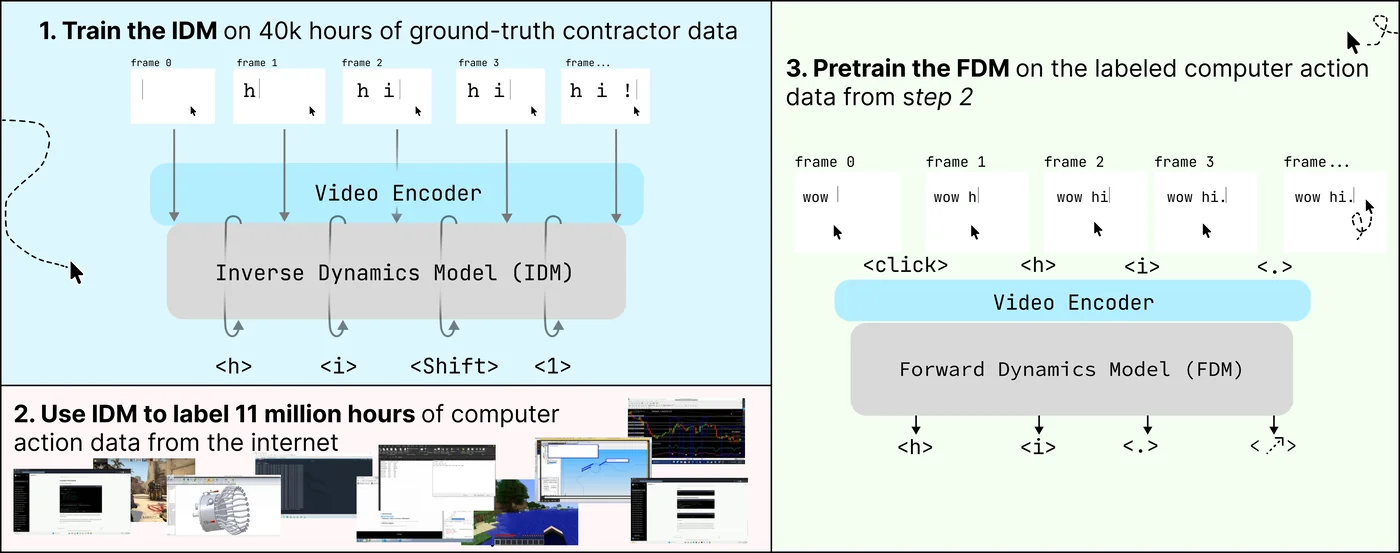
- 1단계 — 역방향 모델(IDM). 사람이 라벨 붙인 4만 시간 영상으로 “화면이 이렇게 변했으면 그 사이에 어떤 마우스·키보드 입력이 있었는지” 거꾸로 맞히는 모델 먼저 학습. 영상만 있으면 클릭·키 입력을 추정 가능한 도구가 생김
- 2단계 — 자동 라벨링. 그 IDM으로 라벨 없는 1100만 시간 영상을 전부 훑어서 “이 시점엔 이런 클릭, 저 시점엔 이런 키 입력”으로 자동 라벨을 붙임. 사람 손이 빠진 자리에서 데이터가 무한히 늘어나는 구조
- 3단계 — 순방향 모델(FDM). 그렇게 라벨 붙인 거대 데이터로 “지금까지 화면이 이랬으면 다음 행동은 이거”를 예측하는 본 모델을 학습. 발표된 FDM-1이 이 결과물
- 특이점 하나. FDM-1은 기존 언어 모델에서 출발해 미세조정한 게 아니라 처음부터 영상·행동 토큰만으로 학습. chain-of-thought 추론도 없고, 사람 텍스트로 추론하는 단계가 본질적으로 빠져 있음. 그래서 추론 지연이 짧음(11ms)
| 항목 | 기존 방식 | FDM-1 |
|---|---|---|
| 학습 데이터 | 외주 라벨 스크린샷 | 화면 녹화 영상 1100만 시간 |
| 다룰 수 있는 맥락 | 수 초 | 최대 1시간 40분 |
| 영상 토큰 효율 | 기준점 | OpenAI 인코더 대비 100배 |
| 처리 속도 | 저프레임 | 30 FPS, 11ms 왕복 |
| 평가 인프라 | 수동 또는 작은 규모 | VM 8만대 동시, 시간당 100만 롤아웃 |
시연 결과는 무엇을 보여주나?
- CAD. Blender에서 다각형 면을 골라 돌출시켜 톱니바퀴를 만드는 작업을 모델이 마우스 연속 움직임으로 직접 수행. 게임 매크로처럼 정해진 좌표를 누르는 게 아니라 매 프레임 마우스를 어디로 옮길지 예측. 핵심 비결은 “성공한 단계(돌출, 면 선택 등)에서 OS 상태를 스냅샷으로 떠놓고, 실패하면 그 시점부터 다시 시도”라는 식의 추론 시점(test-time) 분기 활용
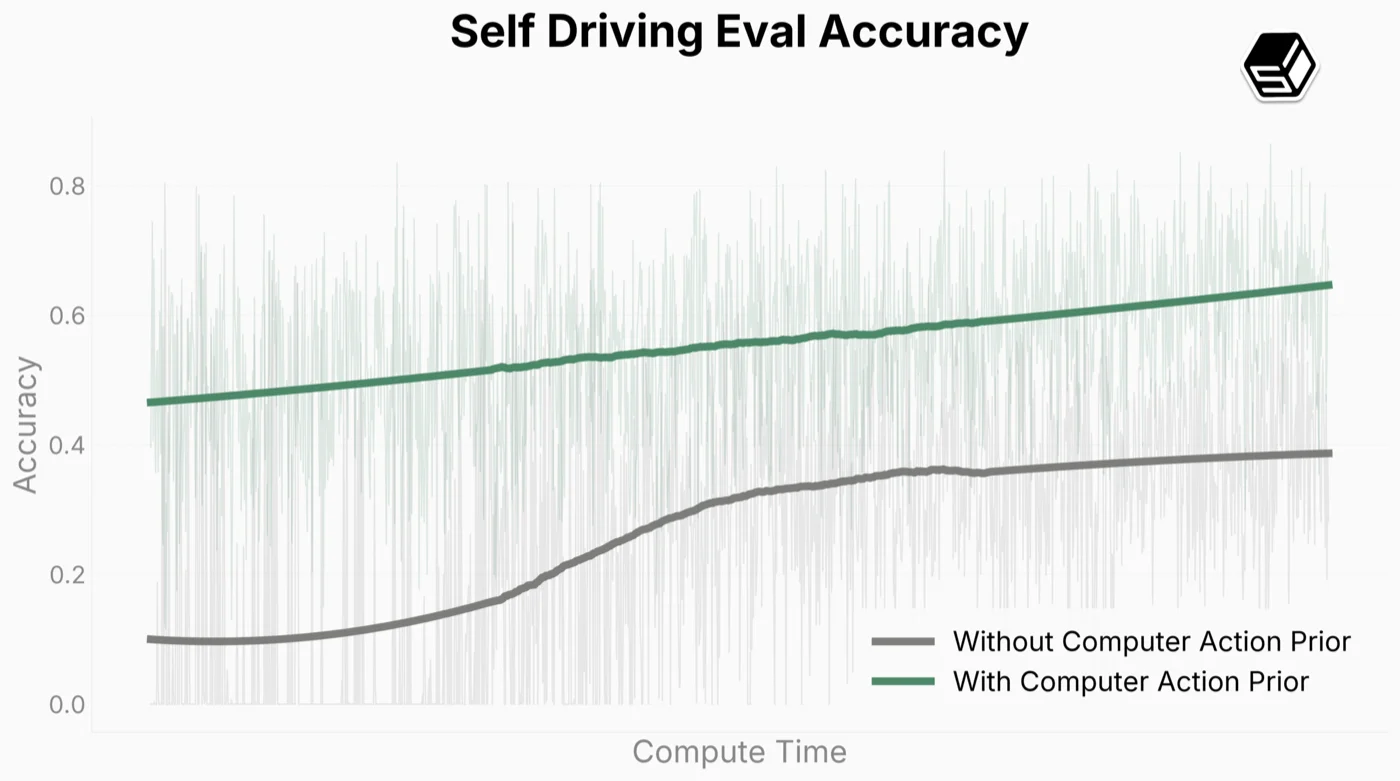
- 자율주행. 같은 모델을 1시간 미만의 운전 화면 데이터로 추가 학습시켰더니 화살표 키만으로 샌프란시스코 한 블록을 돌면서 키 입력 정확도 50% 달성. 영상으로만 학습한 사전훈련이 운전이라는 전혀 다른 도메인에 빠르게 옮겨붙음
- 구현은 오픈소스 자율주행 스택 openpilot의 “조이스틱 모드”를 포크해서 차량을 화살표 키로 제어, 라이브 영상·조향각·브레이크·가속을 한 웹 페이지에 띄우는 식. 모델의 선택지는 정지/좌/우 3지선다. FDM-1을 사전학습 가중치에서 미세조정한 쪽이 처음부터(from scratch) 학습한 쪽보다 정확도와 스케일링 모두 압도
- 차트로 보면 같은 데이터에서 FDM-1을 미세조정한 쪽(파랑)이 영상 인코더만 가진 베이스라인(회색)보다 시작점도 높고 학습 곡선도 더 가파르게 올라감. 컴퓨터 사용 영상 사전학습이 실제 세계 행동에까지 옮겨간다는 신호
- UI 자동 테스트(fuzzing). 은행 앱을 모델이 무작위로 탐색하다가 “송금이 완료된 뒤에도 송금 버튼이 활성 상태로 남아 잔액이 마이너스가 되는 버그”를 자동 발견. 사람 QA가 놓치기 쉬운 상태 조합을 컴퓨터가 대신 훑는 그림
- 단순 무작위 클릭이나 랜덤 키 입력으로는 fuzzing이 안 됨. 사람이 실제로 할 법한 행동을 흉내낼 수 있어야 의미 있는 상태에 도달함. 포킹 VM 인프라로 “새로운 상태에 닿을 때마다 그 시점 OS를 복제해서 가지치기”하는 구조
- 실험 결과 비교에서 마우스 움직임·UI 조작은 IDM 자동 라벨 데이터가 사람 외주 라벨보다 더 잘 됨. 반대로 타이핑이나 언어 이해는 사람 라벨이 여전히 더 나음. 둘을 섞는 게 정답이라는 신호
인프라가 사실상 절반의 비결
- 평가 인프라가 핵심. VM 8만대를 동시에 돌리면서 시간당 100만번 시뮬레이션을 굴림. 각 VM은 vCPU 1코어 + 메모리 8GB짜리 최소 사양 우분투 데스크톱. H100 GPU 한 장이 VM 42대를 동시에 제어
- “포킹(forking) VM” 기술. OS 메모리 상태를 통째로 스냅샷 떠서 새 VM에 그대로 복제. 같은 시작점에서 수천 번 다른 행동을 시도하고 결과를 비교 가능
- 11ms 왕복 지연이 핵심 디테일. 학습 시 모델은 지연을 본 적이 없어서 추론 때 지연이 커지면 분포에서 벗어남. GPU·VM 같은 클라우드 리전 배치, sequence length packing, 저지연 VNC 설정, 디바이스 입력용 커스텀 Rust 바인딩까지 동원
- 이 정도 평가 인프라가 없으면 모델을 만들어도 어떻게 좋아지는지 측정 자체가 안 됨. 글에서 인프라 챕터에 가장 많은 분량을 할애하는 이유
글의 결론은 무엇인가?
- 저자들의 한 줄 요약. “컴퓨터 사용 자동화는 그동안 데이터가 모자라서 못 풀었던 문제(data-constrained)였는데, 이제 데이터가 아니라 컴퓨팅이 병목인 문제(compute-constrained)로 옮겨갔다”
- 같은 문장의 다른 의미. 앞으로는 누가 더 많은 GPU와 VM 인프라를 쏟느냐의 싸움이라는 뜻이기도 함. 결국 “긴 컨텍스트 영상으로 학습 + 거대 평가 인프라”가 표준이 되면 진입장벽이 자본 쪽으로 넘어감
- 마무리 베팅. 저자들은 “10년 안에 AGI가 나올 것”이라 본인들 입장 못박고, 그 길에 컴퓨터 행동 모델이 핵심 부품이라는 자리매김
Claude Computer Use나 OpenAI Operator와 뭐가 다른가?
이 둘은 큰 비전·언어 모델 위에 컴퓨터 사용 능력을 얹는 접근. FDM-1은 처음부터 컴퓨터 사용 자체를 목적으로 영상 위주로 학습한 모델. 짧은 맥락(몇 초~수십 초)에선 비슷해 보일 수 있지만, 1시간짜리 디자인 작업처럼 긴 워크플로에서 차이가 벌어질 거라는 게 저자들의 주장.
1인기업가가 지금 쓸 수 있나?
아직 아님. FDM-1은 비공개고, 평가만 해도 VM 8만대급 인프라가 필요한 자리. 실용적 제품으로 풀려 나오기 전엔 직접 호출 못함. 다만 “긴 맥락 컴퓨터 에이전트”가 가능하다는 신호 자체가 사업 계획에 영향을 줄 수 있음.
그럼 데이터 1100만 시간은 어디서 구한 건가?
글에서 정확한 출처는 명시하지 않음. 인터넷에 공개된 게임 플레이·튜토리얼·소프트웨어 리뷰 영상 등이 가장 그럴싸한 후보. 라이선스·저작권 측면 디테일이 빠져 있어 추후 논쟁 거리가 될 가능성.
1인기업 관점
세 시연 중 1인기업가한테 가장 가까운 건 UI 자동 테스트 데모인 듯. CAD·자율주행은 일반인 일상 업무가 아니지만, 자기 SaaS의 UI를 AI가 무작위로 클릭해 상태 버그를 찾아주는 그림은 본인이 usedesktop 같은 소규모 SaaS를 굴리고 있다면 바로 떠오르는 자리임. 다만 모델은 비공개고 평가 인프라가 VM 8만대급이라 직접 만들 수 있는 자리는 아니고, 결국 누가 이걸 API나 SaaS 형태로 풀어주느냐의 문제라 한 6~12개월 정도 지켜보는 게 맞는 것 같음.
관련: Karpathy: 바이브 코딩과 에이전틱 엔지니어링와 Meta가 직원 키 입력을 AI 학습용으로 추적도 같이 보면 좋습니다.
관련 글
Jerry Tworek: AI lab 자동화와 eval의 끝 (AGI House)
Jerry Tworek가 말한 reasoning model, eval 한계, continual learning을 1인기업 관점에서 정리.
3Blue1Brown: AI 수학 증명은 AGI인가: Dwarkesh
Grant Sanderson이 말한 AI 수학, 증명, 벤치마크 한계. 1인기업도 eval을 볼 때 참고할 관점.
SemiAnalysis: AI의 진짜 100배는 co-design에서 온다 (Sequoia)
AI 추론 비용, InferenceX, GPU/TPU 선택을 1인기업 관점에서 쉽게 정리.
뉴스레터 구독
매주 엄선된 1인기업 뉴스를 이메일로 받아보세요.